In the last article, Why Healthcare Needs a Curated Data Layer, Alex Daniels outlined a core truth: healthcare doesn't have a data shortage, it has a data usability problem.
To underscore this point, consider the findings of Dr. Brian Patterson and his co-authors:
- In 2006, the median patient had 5 notes in their chart; by 2022, that had grown to 359 notes, a 30-fold increase over 17 years.
- By the end of the study period, 1 in 5 patients arriving in the ED had a chart the size of Moby Dick (206,000+ words).
The data aren't the problem. The usability is.
But solving usability isn't just about cleaning data. It requires something deeper: data transformation with deep health native context: Health Native Data Transformation.
This is the process of taking fragmented, inconsistent, multi-format patient data and transforming it into a unified, longitudinal, clinically meaningful record. Data transformation may sound like a single step, but in reality it's a system of capabilities working together. This system of capabilities is what makes Predoc's curated data layer so useful.
Capability 1 | The Master Patient Index: Building the Longitudinal Record
Before you can use patient data, you need to answer a deceptively simple question: Which records belong to the same patient?
This may seem like a simple question, but in reality, patient data is scattered across multiple providers, different systems, and it often leverages inconsistent identifiers.
Think of an identifier as the single source of truth for what counts as a single patient. Seems straightforward, but many of the available identifiers aren't reliable. Think of an identifier as the combination of things like patient name, date of birth, and an additional data point like zip code that help clarify that "John Smith" born on 1/01/1976 in XYZ location is the same as "John Smith" born on 1/01/1976 who now lives in ABC location.
Patients frequently change names (e.g., marriage, divorce), addresses, and insurance information. These changes make it difficult to confidently determine whether two records truly belong to the same person. A Master Patient Index (MPI) solves this by intelligently stitching together records into a longitudinal patient history, even in the presence of these inconsistencies. Every data point contributes to a single, trusted patient record.
Without a MPI: you get duplicate patients, fragmented timelines, and low confidence in identity matching.
Capability 2 | Terminology Mapping: Speaking the Same Clinical Language
Healthcare data doesn't just vary in format, it varies in language. The same concept can be represented across: ICD-10, SNOMED-CT, LOINC, CPT, and with many different iterations on spelling, abbreviations, and free-text variations.
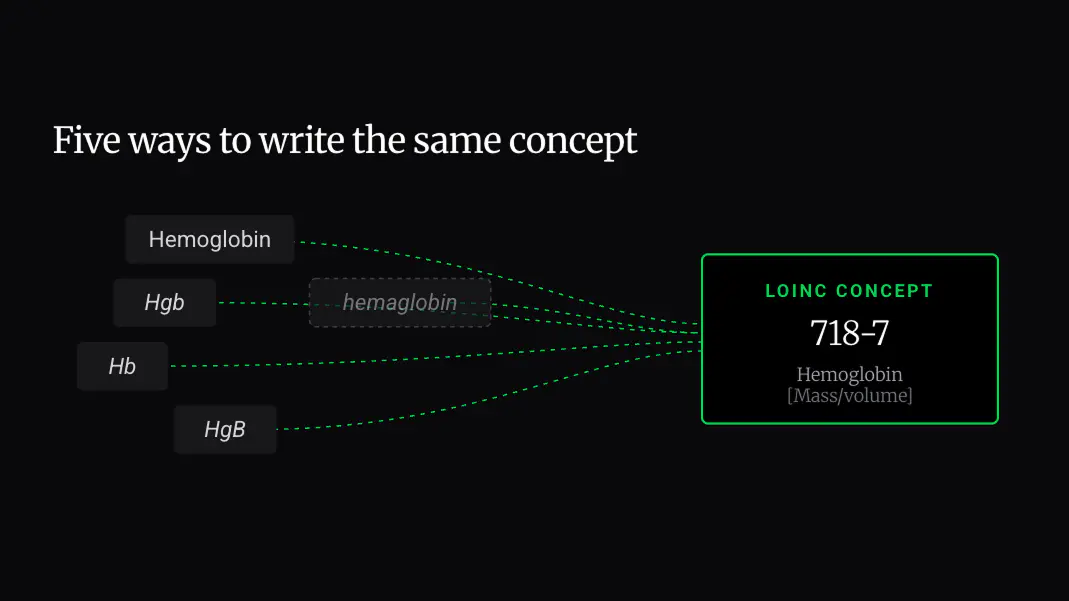
Terminology mapping ensures that all of these variations resolve to a standardized clinical concept. Consider Hemoglobin, for example. It might be represented as Hemoglobin, Hgb, Hb, HgB, Hemoglobin A1c, HbA1c, or even a misspelling like hemaglobin.
Without proper mapping, these can be treated as entirely separate concepts, leading to incomplete lab histories, broken queries, and misleading analytics. And yet, analytics depend on consistency, the ability to properly use AI depends on clarity, and clinical decisions depend on accuracy.
Read the Terminology Mapping deep dive →
Capability 3 | Unstructured Data Extraction: Unlocking What's Trapped
Even when health data are accessible, a massive portion of it is still unstructured. Think: faxed records, scanned PDFs, narrative provider notes.
This is where critical information often lives, and where most systems fail. Because unstructured data isn't just messy, it's contextual. Information isn't neatly labeled. It's embedded in paragraphs, spread across pages, and mixed with irrelevant content. A single document might include: medications buried in a clinical note, lab values listed in a table with inconsistent formatting, diagnoses referenced indirectly in narrative text.
Common extraction methods like OCR or keyword search often fail because you might extract text, but you'll miss the meaning.
Predoc's extraction methodology is built to support extraction of contextual and relevant health data. It can be broken down into three steps:
- Segmentation: convert the document into machine-readable content, then split it into logical document units such as encounters, provider notes, or visit level sections so each can be interpreted in context.
- Classification: determine what clinical content each segment contains and how it should be interpreted.
- Extraction: pull out the relevant information like medications with dosage, frequency, and route, lab values with correct units, diagnoses with standardized terminology.
This process effectively "liquefies" data, turning static documents into usable, queryable information.
Capability 4 | Cross-Modal Synchronization: Aligning the Patient Story
Patient data isn't just fragmented across systems, it's fragmented across modalities. Clinical notes (text), lab results (structured values), medications (orders, histories, administrations), and imaging (temporal changes) each tell a part of the patient story.
Most systems store these data types separately. Even when all the data are present, it's rarely synchronized in time or context. Synchronization requires accounting for inconsistent or missing time data, different granularities, unstructured references, delayed documentation, and duplication — for example, the same clinical event may appear multiple times across sources.
When data is synchronized across modalities: clinicians get a clearer, faster understanding of the patient; analysts can track cause-and-effect relationships; and AI models gain the temporal context they need to be accurate.
Capability 5 | Identity Resolution: Connecting to the Operational Reality
Clinical data doesn't live in isolation, it needs to connect to operational systems like RCM (Revenue Cycle Management).
Identity resolution ensures that transformed clinical data can align with patient census, billing systems, and operational workflows. Systems break when clinical and financial data don't match and records can't be reconciled, so workflows become manual. When identity is resolved correctly, data becomes actionable across the organization.
Capability 6 | Data Standardization: One Input, Many Outputs
Healthcare data comes in many forms, and it is needed in many forms depending on where the user sits within an organization.
To make health data usable, think of a bowtie model: data comes in any format (HL7, CCDA, PDFs, images, etc.), it becomes naturalized and curated to an internal schema, and it can be released or retrieved in any format. The curated data layer is the middle of the bowtie. It makes data accessible, and an organization can determine what format of data is returned to any endpoint.
This means that Predoc's API can be used to integrate with any EHR, but the same data can also feed analytics platforms or become the knowledge base for any AI system. Standardization creates an incredible efficiency where data can be used over and over again without reprocessing.
The Bottom Line
Healthcare data is complex not just because of its volume, but because of its fragmentation, inconsistency, and context.
You can't solve that with storage alone. You can't solve it with AI alone. You solve it by transforming data in a way that is native to healthcare itself.
That's what enables a true curated data layer. And that's what turns raw records into clinical intelligence.