Faster, More Accurate Trial Screening Starts with a Facesheet
How structured clinical summaries are transforming patient eligibility review
Meghan Russell
Clinical Director of Data Analytics
Sean Crosby
Senior Machine Learning Engineer
The Hardest Part of a Clinical Trial Happens Before It Begins
Before a single dose is administered, before a protocol is executed, before a patient is officially enrolled, there's a quieter, more difficult step that determines whether a trial succeeds or stalls: figuring out who actually qualifies. Those closest to the patients know all too well that this may sound simple, but it really isn't.
To determine eligibility, clinical teams need a complete and accurate picture of a patient's medical history. Not just a diagnosis, but everything surrounding it:
- Prior treatments and their outcomes
- Lab values across time
- Comorbidities and exclusion conditions
- Medications, procedures, and timelines
That information rarely lives in one place. Instead, it's buried across hundreds, sometimes thousands, of pages of medical records: scanned PDFs, fragmented provider notes, disconnected systems.
So coordinators do what they've always done: they read.
They manually review chart after chart, piecing together the patient's story, answering eligibility questions one by one. It can take 2 to 8 hours per patient, and that's for a single protocol.
"One of the greatest frustrations in clinical trial screening is the effort and time required to track down records and piece together a patient's history, often only to find the patient isn't eligible. After hours of that kind of work, it becomes clear there has to be a more efficient way to get to that answer," explains Meghan Russell, Clinical Director of Data Analytics.
Multiply that across dozens of patients and multiple trials, and the challenge becomes clear:
Clinical trials don't just struggle to find patients, they struggle to understand them fast enough.
Enter: the Predoc Facesheet
A clinical summary, which transforms raw medical records into a structured, clinically meaningful summary of a patient's history. Instead of forcing coordinators to extract facts manually, it presents:
- Key clinical information organized around eligibility criteria
- Direct answers to inclusion/exclusion questions
- Citations back to the source documents, so nothing is a black box
In other words, it doesn't replace clinical decision making, but it makes it much faster.
With a Facesheet, a coordinator no longer has to ask, "Where in this chart is the answer?" They can instead ask, "Do I agree with this answer?" That shift, from searching to verifying, is where the time savings and clarity emerge.
A new way of screening patients: the elements of a facesheet
Each Predoc facesheet is specifically developed to cover a unique set of trial protocols, or in a care environment, chart prep questions. The facesheet contains a list of those questions, a yes/no answer, rationale supporting that answer, and one, or multiple, source page references to point to where the answer was spotted.
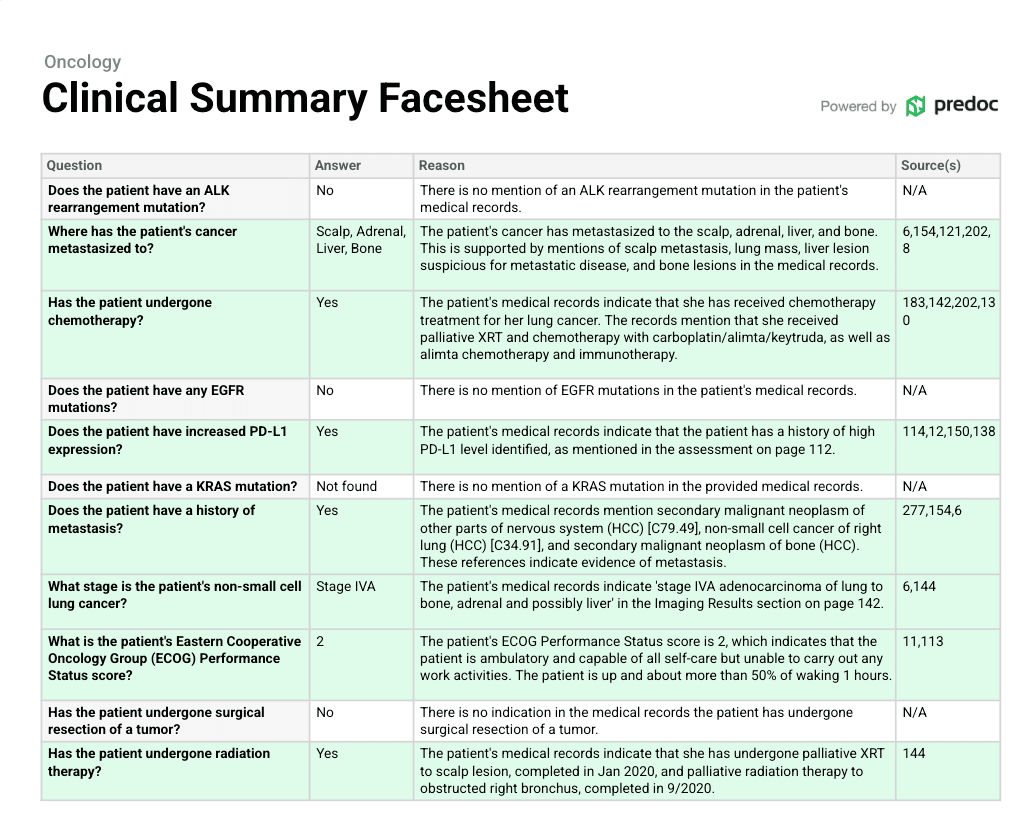
This construct allows a clinical research coordinator or investigator to rapidly scan whether the patient might easily be disqualified based on their prior health history. Then, it expedites the validation process by pointing to source pages where researchers can verify each individual response.
Facesheets promote both accuracy and speed in evaluation
Accuracy is the foundation of Predoc Facesheets, with speed emerging as a strong secondary advantage for trial screening teams. To quantify this impact, the Predoc team conducted a study.
The analysis included:
- 1,569 unstructured PDF records
- 1,118 semi-structured HIE records
- 54 sets of trial eligibility criteria
- Tens of thousands of eligibility questions, each validated against source documentation
Every answer produced by the system included traceable citations and was reviewed against human clinical judgment.
"We wanted to show not only that the system was quick, but also that it was highly accurate," suggests Senior ML Engineer, Sean Crosby. "We know that CRCs and clinicians, alike, can face burnout periods in a day, week, or month that diminish their own accuracy, but for our models, this was unacceptable."
The results speak for themselves, the system achieved:
- 98.1% accuracy on unstructured PDF records
- 99.7% accuracy on HIE records
Critically, false negatives were extremely low (as low as 0.24%), meaning the system rarely missed eligible patients, a key requirement in trial recruitment. Across the majority of protocols, accuracy exceeded 95%, demonstrating consistent performance even as criteria and record types varied.
In addition to accuracy, facesheets also represent a distinct advantage with respect to speed. Compared to the hours spent on human review, Predoc's facesheets are often generated in less than a minute with even the largest, most complicated patient data sets processing in fewer than 10. This represents a fundamental shift in the time it takes to qualify or disqualify a single patient.
Clinical trials will always demand rigor. They will always require complete patient data, careful interpretation, and clinical judgment. That doesn't change.
What can change, and what must change, is how that information is accessed and understood.
For too long, trial screening has depended on a slow, manual process of searching through fragmented records, asking coordinators and clinicians to do the painstaking work of assembling a patient's story from scratch. It's not just inefficient, it's a barrier to faster enrollment, higher trial throughput, and ultimately, getting therapies to patients sooner.
Predoc Facesheets offer a different starting point.
About the Authors
Meghan Russell
Clinical Director of Data Analytics
Sean Crosby
Senior Machine Learning Engineer

Want to Learn More?
See how healthcare organizations are putting these ideas into practice with Predoc.
View Customer Stories→